
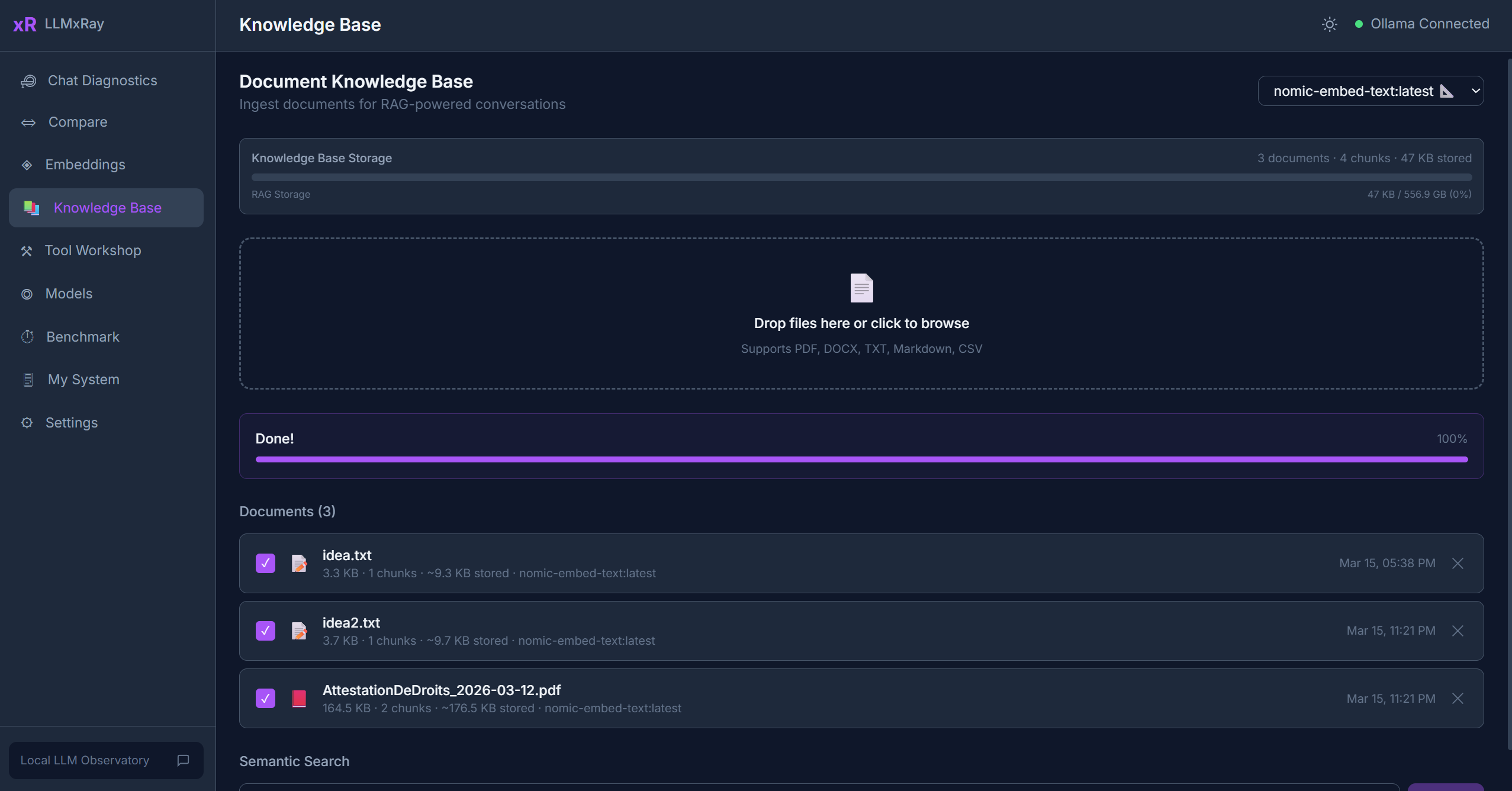
Base de Connaissances
La page Base de Connaissances implémente un pipeline RAG (Retrieval-Augmented Generation) complet et local. Téléversez vos documents, générez leurs embeddings et recherchez en langage naturel -- le tout stocké dans votre navigateur.
Élément de la barre latérale : Base de Connaissances Route : /rag
Qu'est-ce que le RAG ?
RAG signifie Retrieval-Augmented Generation (Génération Augmentée par la Récupération). Au lieu de se fier uniquement à ce sur quoi un modèle a été entraîné, le RAG permet de lui fournir des extraits pertinents de vos propres documents. Le modèle utilise ensuite ces extraits comme contexte pour donner des réponses plus précises et ancrées dans vos données.
Téléversement de documents
Cliquez sur Télécharger et sélectionnez un ou plusieurs fichiers. Formats pris en charge :
| Format | Extension | Analyseur |
|---|---|---|
.pdf | pdfjs-dist (chargé à la demande) | |
| Word | .docx | mammoth |
| Texte brut | .txt, .md | Natif |
| CSV | .csv | papaparse |
Le pipeline d'ingestion
Après le téléversement, chaque document passe par trois étapes :
- Analyse -- Extraction du texte brut depuis le format de fichier
- Découpage -- Fractionnement du texte en segments chevauchants (taille et chevauchement configurables)
- Embedding -- Génération d'un vecteur pour chaque segment à l'aide du modèle d'embedding choisi
La progression est affichée par document. Une fois terminé, le statut du document passe à "Prêt".
Recherche
- Saisissez une requête en langage naturel dans la barre de recherche.
- Les résultats apparaissent classés par similarité cosinus -- les segments les plus pertinents sémantiquement en premier.
- Chaque résultat affiche :
- L'extrait de texte correspondant
- Le nom du document source
- Le score de similarité
- Les métadonnées (numéro de page, section, positions dans le texte)
Gestion des documents
- Activer/Désactiver -- Basculez les documents pour la recherche. Les documents désactivés ne sont pas inclus dans les résultats.
- Supprimer -- Supprime un document et tous ses segments d'IndexedDB.
- Indicateurs de statut -- Affiche l'étape de traitement (analyse, découpage, embedding, prêt, erreur).
Stockage
Tout est stocké dans IndexedDB, la base de données intégrée de votre navigateur :
- Zéro coût -- aucun service externe nécessaire
- Zéro configuration -- fonctionne immédiatement
- Les données restent sur votre machine
- Survit aux actualisations du navigateur (mais pas à l'effacement des données du navigateur)
Intégration avec le Chat
Lorsque vous avez des documents dans la Base de Connaissances, les segments pertinents peuvent être automatiquement inclus comme contexte dans vos conversations de chat, ancrant les réponses du modèle dans vos données.
Astuces
- Des segments plus petits (200-400 tokens) tendent à produire des résultats de recherche plus précis.
- Le modèle d'embedding compte --
nomic-embed-textfonctionne généralement bien pour les textes en anglais. - Les PDF volumineux prennent du temps à traiter. L'interface affiche la progression pour que vous puissiez suivre le pipeline.
- Vous pouvez télécharger plusieurs documents et effectuer des recherches sur l'ensemble simultanément.