
Diagnostics de Chat
La page Diagnostics de Chat est le cœur de LLMxRay. Elle combine une interface de chat complète avec une analyse approfondie en temps réel de chaque token produit par le modèle.
Élément de la barre latérale : Diagnostics de Chat (premier élément) Route : /
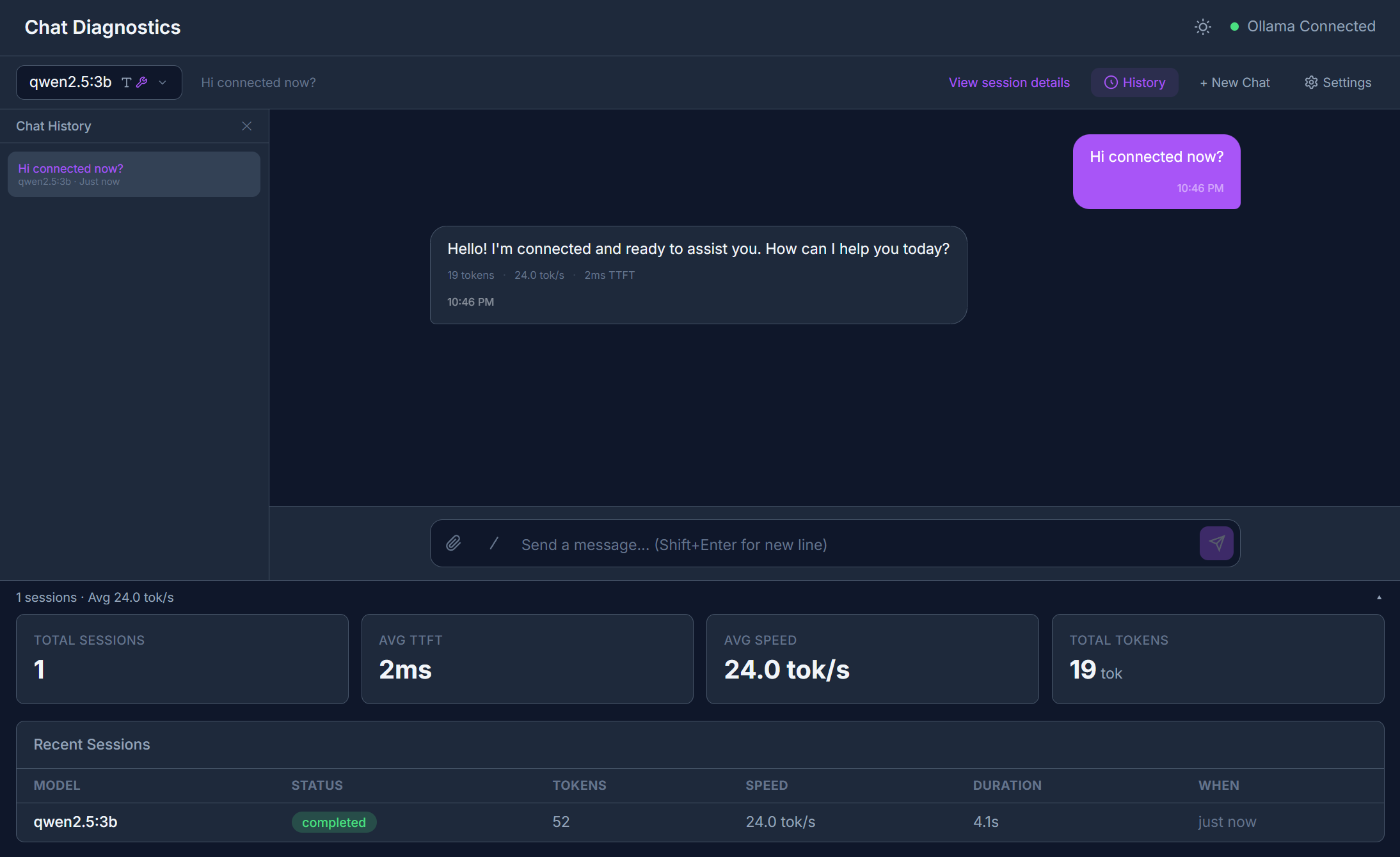
Vue d'ensemble de l'interface
La page est divisée en deux zones :
- Panneau gauche -- Liste des sessions affichant toutes les conversations passées avec horodatage, noms de modèles et nombre de tokens.
- Panneau droit -- Zone de chat active avec saisie de message, sortie en streaming et onglets de détail de session.
Démarrer une conversation
- Sélectionnez un modèle dans le menu déroulant des modèles en haut. Les modèles d'embedding sont automatiquement filtrés -- seuls les modèles capables de chat apparaissent.
- Saisissez votre message dans la zone de texte.
- Appuyez sur Entrée ou cliquez sur Envoyer.
Les tokens arrivent un par un avec une coloration par confiance : chaque token est teinté en fonction de la vitesse à laquelle le modèle l'a produit. Tokens rapides = confiance élevée (plus vert). Tokens lents = confiance faible (plus orange/rouge).
La confiance est une approximation
Comme le endpoint /api/chat d'Ollama n'expose pas les logprobs des tokens, LLMxRay approxime la confiance à partir de la latence inter-tokens. Cela est clairement indiqué dans l'interface. Pour de vrais logprobs, utilisez la fonctionnalité Benchmark.
Fonctionnalités
Rendu Markdown
Les réponses du modèle sont rendues en Markdown enrichi avec coloration syntaxique des blocs de code.
Fichiers joints
Cliquez sur le bouton de pièce jointe pour télécharger des fichiers. Pour les modèles de vision (comme LLaVA), vous pouvez coller ou télécharger des images directement -- le modèle les analysera.
Commandes slash
Tapez / dans la zone de saisie pour voir les commandes slash disponibles pour des actions rapides.
Conversation multi-tours
Chaque conversation conserve l'historique complet des messages. Le modèle voit tous les messages précédents comme contexte.
Portes de qualite des reponses
Chaque reponse de l'assistant est automatiquement analysee par cinq detecteurs cote client. Lorsque des problemes sont detectes, de petits badges colores apparaissent sous les metriques de la reponse :
| Detecteur | Condition | Severite |
|---|---|---|
| Repetition | >50% de 4-grammes repetes | Echec (rouge) |
| Repetition | >30% de 4-grammes repetes | Attention (jaune) |
| Refus | Correspond a 8 modeles de refus courants | Attention |
| Charabia | >40% de caracteres non-ASCII (texte >20 car.) | Attention |
| Vide | 0 mots | Echec |
| Vide | 1-9 mots | Attention |
| Troncature | Limite de tokens atteinte ou >90% du budget sans fin propre | Attention |
Un petit point colore apparait egalement dans la ligne de metriques pour un scan rapide. Si tous les controles passent, rien de supplementaire n'est affiche.
Toute l'analyse est cote client
Les controles de qualite s'executent instantanement dans votre navigateur sur le texte de la reponse affichee. Aucun appel API, aucun service externe.
Analyse approfondie des sessions
Cliquez sur une session dans le panneau gauche pour explorer six onglets d'analyse :
Onglet Stream
Chaque token avec ses données de timing affiché dans une liste déroulante. Au-dessus de la liste de tokens, un tableau de bord de métriques affiche :
- TTFT (Time to First Token) -- Temps mis par le modèle pour commencer à répondre
- Tokens/sec -- Vitesse de génération
- Total tokens -- Nombre de tokens (prompt + completion)
- Graphique de latence -- Chronologie visuelle des délais inter-tokens
Onglet Raisonnement
Si vous utilisez un modèle de raisonnement comme DeepSeek-R1, les blocs <think> sont automatiquement analysés et affichés étape par étape. Chaque étape de raisonnement est catégorisée comme pensée, observation, action, conclusion ou réflexion.
Onglet Introspection
Visualisations des activations de couches, cartes de chaleur d'attention et architecture du modèle.
Données illustratives
Ces visualisations utilisent des données synthétiques pour montrer à quoi ressemblerait une véritable introspection. Elles sont clairement étiquetées "Illustratif" dans l'interface. L'introspection réelle nécessite un accès aux mécanismes internes du modèle qu'Ollama n'expose pas.
Onglet Outils
Une chronologie de tous les appels d'outils effectués par le modèle pendant la conversation, montrant :
- Nom de l'outil et paramètres
- Résultat de l'exécution
- Durée
Onglet Agent
Un graphe de flux d'états montrant comment un prompt de type agent a progressé à travers les étapes de planification, d'appels d'outils et de synthèse.
Onglet Prompt
Une analyse anatomique de votre prompt montrant :
- Les sections identifiées (système, utilisateur, contexte, outils, exemples)
- Le nombre de tokens par section
- L'analyse de la structure globale
Astuces
- Persistance des sessions -- Toutes les conversations sont stockées dans IndexedDB et survivent aux actualisations du navigateur.
- Changement de modèle -- Vous pouvez changer de modèle en cours de session. Le nouveau modèle verra l'historique complet de la conversation.
- Performance -- Le store de tokens utilise
shallowRefpour garantir les performances avec des milliers de tokens.