
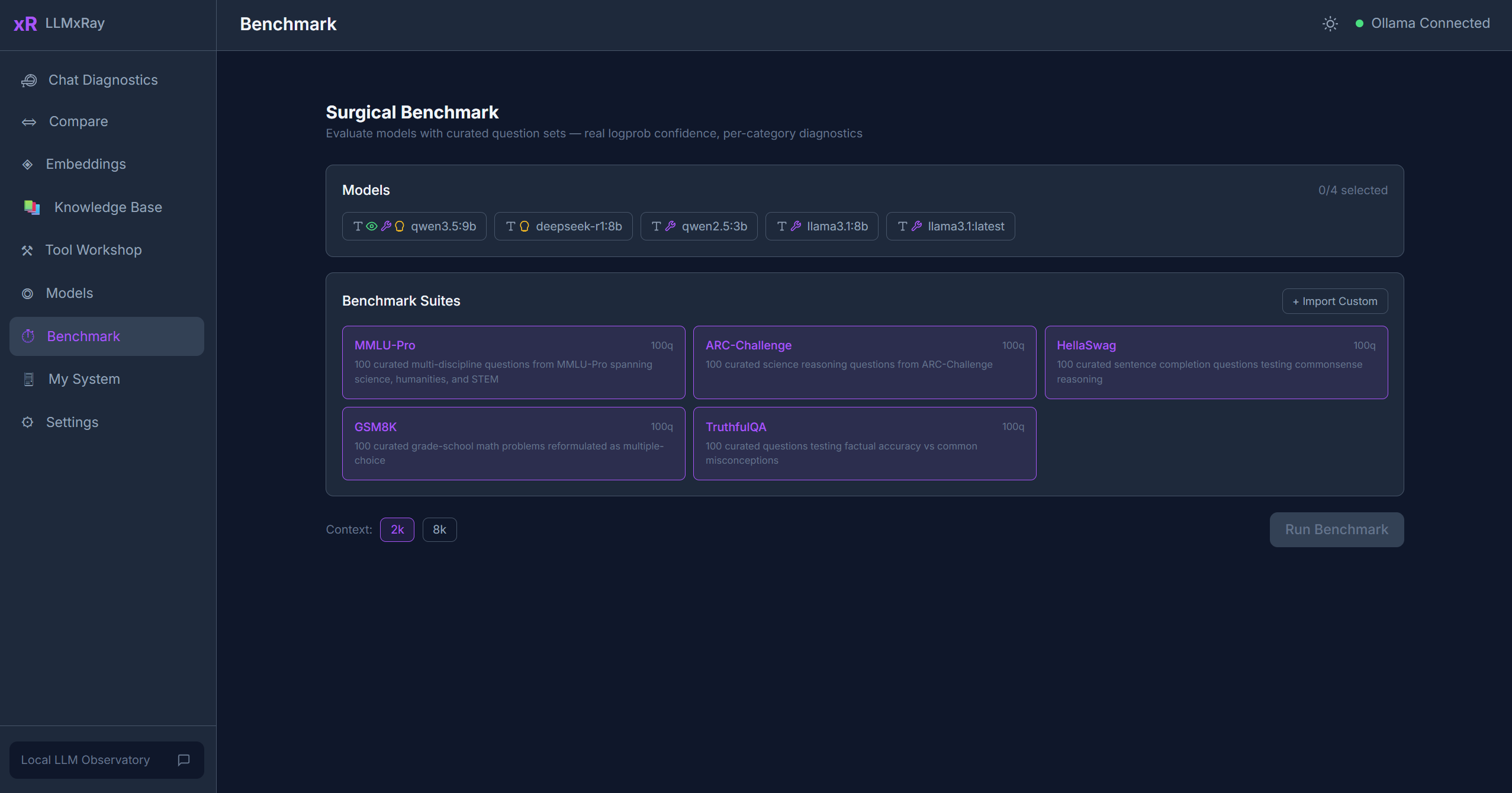
Benchmark
La page Benchmark exécute des évaluations standardisées sur vos modèles locaux en utilisant de vrais logprobs de tokens, vous fournissant des données de performance objectives.
Élément de la barre latérale : Benchmark Route : /benchmark
Qu'est-ce que le Benchmark Chirurgical ?
Contrairement aux benchmarks classiques qui vérifient simplement si la réponse est correcte, le Benchmark Chirurgical de LLMxRay capture de vrais logprobs de tokens via le endpoint compatible OpenAI d'Ollama (/v1/chat/completions). Cela vous donne des données de confiance authentiques pour chaque réponse, et pas seulement la précision.
Suites de tests intégrées
| Suite | Questions | Ce qu'elle évalue |
|---|---|---|
| ARC | Raisonnement scientifique | Questions de sciences niveau collège |
| GSM8K | Problèmes mathématiques | Raisonnement arithmétique en plusieurs étapes |
| HellaSwag | Complétion de phrases | Raisonnement de bon sens |
| MMLU-Pro | Multi-disciplines | Connaissances académiques larges dans différents domaines |
| TruthfulQA | Véracité | Résistance aux idées reçues erronées |
Lancer un benchmark
- Sélectionnez un modèle dans le menu déroulant.
- Choisissez une ou plusieurs suites de tests.
- Cliquez sur Lancer. Le benchmark diffuse les résultats en temps réel.
Pendant l'exécution, vous pouvez voir :
- Progression en direct -- Nombre de questions, précision actuelle
- Résultats par question -- Correct/incorrect, réponse du modèle, scores de confiance
- Données de latence -- TTFT et tokens/sec par question
Modèles de raisonnement
Pour les modèles de raisonnement comme DeepSeek-R1, le benchmark utilise des budgets de tokens dynamiques -- accordant au modèle plus de tokens pour ses blocs <think> sans les compter dans la réponse. Cela garantit que les modèles de raisonnement ne sont pas pénalisés pour avoir montré leur cheminement.
Visualisation des résultats
Après complétion, les résultats sont affichés sous forme de :
- Score de précision -- Pourcentage global de bonnes réponses
- Détail par catégorie -- Précision par domaine au sein de chaque suite
- Graphique radar -- Comparaison visuelle entre les catégories
- Distribution de confiance -- Histogramme des scores de confiance basés sur les logprobs
Comparer les résultats
Lancez la même suite sur plusieurs modèles pour comparer :
- Quel modèle est le plus précis sur quels sujets
- Calibration de la confiance -- une confiance élevée correspond-elle à des réponses correctes ?
- Compromis vitesse vs. précision
Les résultats sont stockés dans IndexedDB, ce qui vous permet de comparer entre les sessions.
Suites personnalisées
Cliquez sur Importer pour charger une suite de benchmark personnalisée. Le format attendu est un fichier JSON contenant :
- Nom et description de la suite
- Tableau de questions, chacune avec : texte de la question, choix de réponses, index de la réponse correcte et catégorie optionnelle
Vous pouvez aussi créer des suites personnalisées directement dans l'application avec le Constructeur de Suites de Benchmark — ajoutez des questions manuellement ou laissez un modèle local les générer pour vous. Consultez le guide du Constructeur de Benchmark pour plus de détails.
Exporter les resultats
Cliquez sur le bouton Exporter dans l'en-tete des resultats pour telecharger vos donnees de benchmark en JSON, CSV ou Markdown. Le JSON inclut les donnees structurees completes pour le scripting et l'analyse ; le CSV fournit des donnees tabulaires plates pour les tableurs ; le Markdown vous donne un rapport formate pret a coller dans vos documents. Consultez le guide d'export pour plus de details sur toutes les options d'export et le partage sur GitHub Discussions.
Astuces
- Les logprobs nécessitent le endpoint
/v1-- Cela utilise l'API compatible OpenAI d'Ollama, et non le endpoint natif/api. - Commencez par des suites plus petites -- Démarrez avec un sous-ensemble pour estimer la durée d'une exécution complète.
- Reprise possible -- Si un benchmark est interrompu, vous pouvez reprendre là où il s'est arrêté.
- Comparer les quantifications -- Lancez le même modèle en Q4 et Q8 pour mesurer l'impact sur la précision.